Hi - I just posted about the same issue just a few weeks back. here - AI Bridge Docker 2.0.5 doesn't allow a certain amount of metadata devices to be created
Although there may have been possibly a connecting issue that was fixed (removing a processing server configuration line in the database) the original issue still remains.
After re-building the bridge, I successfully was able to subscribe all our cameras to their metadata device. It ran smoothly all last week and over the weekend. Yesterday I brought down the bridge for an update then brought back up.
Today I was subscribing more cameras to their metadata stream when the same thing happened. The recording server crashed, and then it was stuck in a reboot loop. We were off line for over 2 hours.
Since the AI Bridge is too unstable for production, we are going to be putting this on hold till at least we can pinpoint the problem and fix it, or wait for an update to the AI bridge. (The processing server side). The back end Linux, docker compose has no issue. The issue is on the Front end GUI when ticking the metadata boxes to subscribe cameras to.
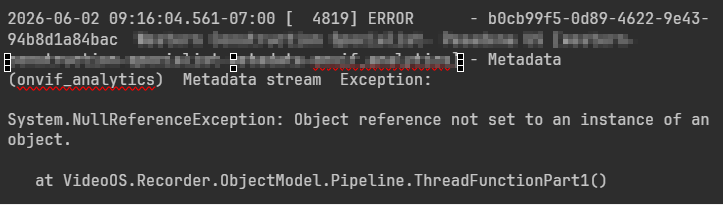
The error is the same as last time:
System.NullReferenceException**: Object reference not set to an instance of an object.**
***at VideoOS.Recorder.ObjectModel.Pipeline.ThreadFunctionPart1()
I’ve attached a snippet of when things went wrong with the error from DeviceHandling.log
DeviceHandling2.log (11.6 KB)
I’m not sure if this is something in particular with our system, or if anyone has seen this from others.
I have a testing lab for the AI bridge, but I don’t have the amount of cameras to add to it to try and replicate the production system.
Milestone support wasn’t much support other then shutting down the recording server, and telling us to remove the metadata devices. But once we shutdown the recording server, we could not remove any metadata devices, the Management client would just hang.
The only fix I could think of is removing the configuration database line that I discovered earlier, that fixed another issue in the previous post. I’m not sure if that helped, but when the recording server was brought back online, it stopped rebooting and recovered. Now we have metadata devices that are in the system, that when we try and remove, we can’t. The management client will just freeze up. We currently have a lot of logs generating that say VPS cannot connect to the recording server. here is a snippet:
2026-06-02 10:55:23.149-07:00 [ 474] ERROR - 71595fd3-23af-41b3-8aa7-81619d18978a VpsThread - VpsThread - Error: Unable to connect to the remote server
2026-06-02 10:55:23.155-07:00 [ 474] ERROR - ed1cf429-d2eb-464a-99bb-6be3bbf19c8b VpsThread - VpsThread - Error: Unable to connect to the remote server
2026-06-02 10:55:23.173-07:00 [ 474] ERROR - 73c69cdb-2ecb-498d-9c55-ddb2561792d9 VpsThread - VpsThread - Error: Unable to connect to the remote server
2026-06-02 10:55:23.218-07:00 [ 474] ERROR - 31c126cd-dcfd-4f19-85ab-cb1c1c7239e1 VpsThread - VpsThread - Error: Unable to connect to the remote server
2026-06-02 10:55:23.329-07:00 [ 474] ERROR - cc574514-10ec-4b17-ab08-bd6668f04122 VpsThread - VpsThread - Error: Unable to connect to the remote server
Since this seems to happen on random metadata devices, its hard to pinpoint what the issue is. This problem is a dead stop for us a company that manages and monitors over 500 cameras in the security field.
From a high level view - it seems to be injecting bad data/no data that the database cannot accept or passing along a null object that wasn’t caught. At the very least I imagine that it should have at least some exception handling to refute any malformed data being injected. Creating and subscribing to metadata devices should not cause a catastrophic failure of the system.
If there are anymore logs you need, let me know. The docker logs on the AI bridge linux end, seem to contain the same as last time. Just generic logs showing when the recording server stopped communicating.
Again, I would love for this to be fixed. And if there is anything you need for me, let me know
Vince